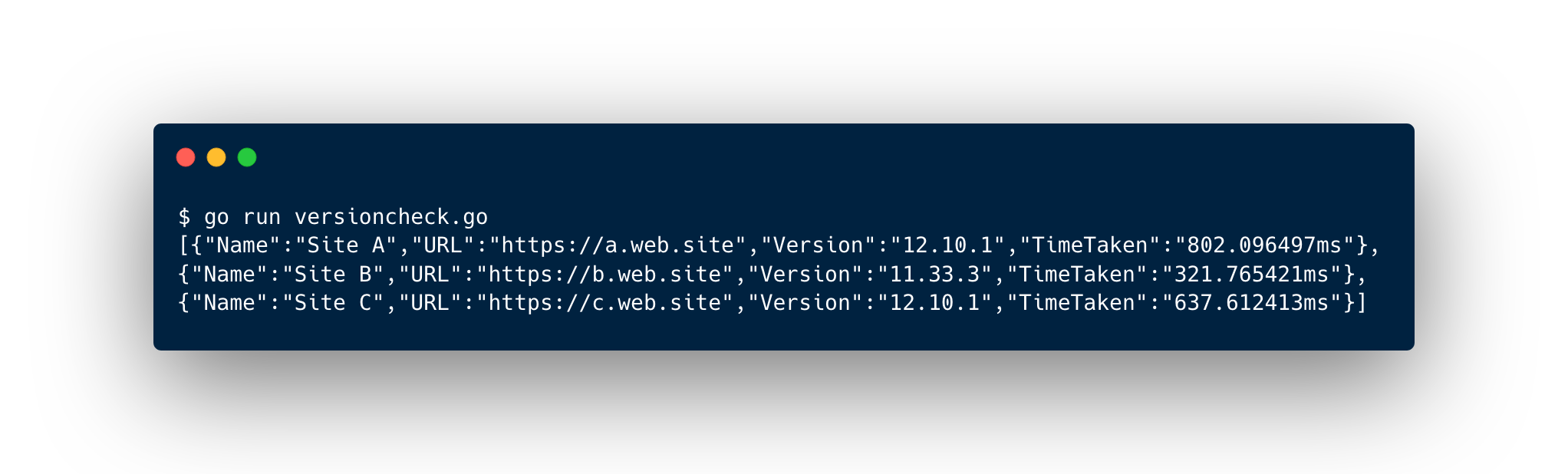
My current work requires keeping track of more than a dozen live websites and making sure that their versions are kept up to date. We have employed a small Go program to make this possible, which enable us to scrape the generator meta tags on the websites and thereby get the version number1.
The code is simple and uses Goroutines to let us concurrently connect to the sites. The code we use in prod is a bit more specialised, but I've reproduced a version that captures the essentials below:
package main
import (
"encoding/json"
"io/ioutil"
"net/http"
"os"
"regexp"
"time"
)
// Site type holds information about sites
type Site struct {
Name, URL, Version, TimeTaken string
}
var sites = []Site{
{"Site A", "https://a.web.site", "N/A", ""},
{"Site B", "https://b.web.site", "N/A", ""},
{"Site C", "https://c.web.site", "N/A", ""},
}
// Parser type holds information about the parsing
type Parser struct {
url, body string
}
func (p *Parser) setURL(url string) {
p.url = url
p.body = ""
}
Site is simply a struct that holds info about the particular site, and fields
to capture the version and the time taken to do the scrape2.
We've initialised a slice of sites with the URLs we need to scrape.
The Parser simply encapsulates parsing behaviour, and has two more methods,
reproduced below. For each scrape, we initialise a new parser.
func (p *Parser) getMatches(regexString string, index int) string {
regex, _ := regexp.Compile(regexString)
matches := regex.FindStringSubmatch(p.body)
if len(matches) == index+1 {
return matches[index]
}
return "N/A"
}
func (p *Parser) getVersion() string {
res, err := http.Get(p.url)
if err != nil {
return "Fetch Error"
}
body, err := ioutil.ReadAll(res.Body)
res.Body.Close()
if err != nil {
return "Parse Error"
}
p.body = string(body)
return p.getMatches("(<meta name=\"generator\" content=\")([^\"]+)", 2)
}
getVersion() simply gets and reads the page body, and getMatches() is a method
to try and match the generator tag regex and return the value of the tag.
Now, we get to the main function and the getSiteVersion() goroutine:
func getSiteVersion(key int, done chan<- bool) {
start := time.Now() // to check the time taken
site := Parser{}
site.setURL(sites[key].URL)
sites[key].Version = site.getVersion()
sites[key].TimeTaken = time.Since(start).String()
done <- true
}
func main() {
done := make(chan bool)
for index := range sites {
go getSiteVersion(index, done)
}
for i := 0; i < len(sites); i++ {
<-done
}
enc := json.NewEncoder(os.Stdout)
enc.Encode(sites)
}
getSiteVersion() gets called in a loop, initialises the Parser, does the scrape,
and does simple time keeping of how long a scrape takes. We don't use a mutex
when accessing the sites slice here because each element is only accessed by one
Goroutine, but if this was not the case a mutex would be essential here.
In main(), we're simply using a channel called done to make sure all the
Goroutines are done executing before we quit the application, and as a final step
we output the sites slice as JSON. As an alternative, a WaitGroup can be used.
This is sadly the only piece of Go code I have written at for work, but it does
its job admirably, and I would highly recommend Go for tasks like these.